[Docker] 1. 도커를 왜 쓸까? 도커가 뭔데?
들어가면서,
서버 스터디를 하면서 '클라우드에 도커를 올려라'라는 말을 듣고, 듣긴 들은 것 같은데 대체 도커가 뭔지를 몰랐다. 단어 하나만 듣고 서버(NHN TOAST 클라우드)에 여자저차 올리긴 했지만 완벽한 개념을 숙지하지 못하고 마구잡이로 올린 탓에 의미가 없었다.
다들 도커를 접하는 많은 이유가 있겠지만, 도커, 이미지, 컨테이너 등 기본적인 개념을 알고 '왜' 쓰는지 알아야 할 것 같아서 정리해보았다.
도커의 등장 전,
기존에 서버를 관리하는 것은 매우 어려웠고 복잡한 영역이어서, 새 서버를 세팅하려면 그때마다 config등의 구축환경을 다시 세팅하고, 그 후에도 리눅스 버전이나 환경의 변화가 생기면 충돌이 일어나기 쉽상이었다.
한 서버에 다수의 프로그램을 설치하면 라이브러리, 포트 충돌을 고려한 설치가 굉장히 어려웠고, 마이크로서비스 아키텍쳐, DevOps 등의 등장으로 서버 관리는 더 어려워졌다.
도커의 등장,
이후 도커의 등장으로 서버 관리의 방식은 완전히 바뀌었다.
도커는 컨테이너 기반의 오픈소스 가상화 플랫폼이다. 컨테이너 안에는 다양한 프로그램, 실행 환경을 '컨테이너'라는 개념으로 추상화하고 클라우드, PC 등 어디서든 실행할 수 있다. 구글에서는 모든 서비스들이 20억개의 컨테이너로 동작한다고 한다.
VM vs Docker,
컨테이너는 격리된 공간에서 프로세스가 동작하는 기술이다. 기존의 가상화 방식은 OS를 가상화하는 것이었다. VMware 등의 가상머신은 Host OS 위에 Guest OS 전체를 가상화한다. 이 방식은 사용법도 간단하고 여러가지 운영체제를 가상화할 수 있지만 무겁고 느리기 때문에 운영환경의 사용에는 적합하지 않았다.

VM vs Docker
이후 CPU의 가상화 기술을 이용한 반가상화 방식이 등장한다. Guest OS가 필요하지만 전체 OS를 가상화하는 방식이 아니어서 성능은 향상되었다. 이 기술은 OpenStack, AWS 등의 클라우드 서비스의 가상 컴퓨터 기술의 기반이 되었다.
전가상화, 반가상화 모두 성능 문제가 있었다. 이를 개선한 프로세스 격리 방식이 등장한다. 리눅스에서 리눅스 컨테이너라고 하며 단순하게 프로세스를 격리시키는 방식이기 때문에 가볍고 빠르게 동작한다. CPU나 메모리 등의 자원을 프로세스가 필요한 만큼만 할당하고 더 필요하면 그때마다 추가적으로 할당하기 때문에 성능적인 손실이 거의 없었다.
하나의 서버에 다수의 컨테이너를 실행하면 서로 영향을 주지 않고 독립적으로 실행된다. 실행 중인 컨테이너에 접속하며 명령어 입력, 패키지 설치, 사용자 추가 등 모든 작업을 할 수 있다. 컨테이너를 만드는 시간은 길어야 2초로 가상머신보다 훨씬 빠르다.
이 전에도 프로세스 격리 방식의 가상화 기술(LXC, Jail 등)이 있었지만 성공하지는 못했다. 도커는 LXC를 기반으로 시작해서 이 후 자체적인 libcontainer 기술을 사용했고 runC 기술에 합쳐졌다. 도커가 성공한 이유는 존재하는 좋은 기술들을 잘 포장해서 오픈 소스로 배포했기 때문이 아닐까.
Image, Container,

Docker Container
도커에서 가장 중요한 개념은 컨테이너, 이미지이다. 이미지는 컨테이너 실행에 필요한 파일, 설정값을 모두 포함하고 있는 것이고 변하지 않는다. 이미지를 실행한 것이 컨테이너이고 여기서 추가, 변화되는 값은 컨테이너에 저장된다. 같은 이미지로 다수의 컨테이너를 생성할 수 있고 컨테이너의 변화가 생겨도 이미지에는 영향을 주지 않는다.
예를 들어 CentOS 이미지는 CentOS를 실행하기 위한 모든 파일, 설정값을 가지고 있고, Tensorflow 이미지 안에는 Tensorflow, Python, Jupyter 등 딥 러닝에 필요한 환경이 모두 들어가 있다. 이미지는 컨테이너를 실행하기 위한 모든 정보를 가지고 있기 때문에 개발 환경 등의 구축을 위해서 이것저것 설치하고 설정할 필요가 없다. 새로운 서버가 추가되면 만들어 놓은 이미지를 다운받고 컨테이너만 생성하면 된다.
도커 이미지는 Dockerhub에서 업로드, 다운로드 할 수도 있다. 현재 공개된 이미지는 50만개가 넘고 누구나 쉽게 명령어를 이용하여 이미지를 만들고 배포하고(push) 다운로드(pull)받을 수 있다.
Layer,
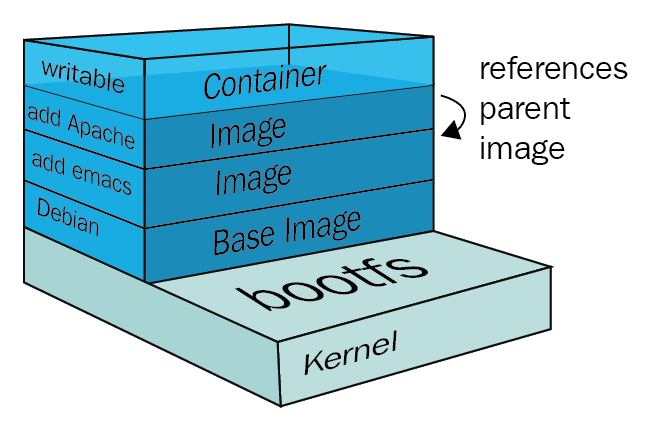
Docker Layer
도커 이미지는 컨테이너 실행에 대한 모든 정보를 담고 있기 때문에 용량이 매우 크다. 따라서 기존의 이미지에 파일 하나를 추가했다고 수백메가가 넘어가는 이미지를 다시 다운로드한다면 매우 비효율적일 수 밖에 없다.
도커는 레이어; Layer라는 개념을 사용한다. 유니온 파일 시스템을 이용하여 다수의 레이어를 하나의 파일시스템으로 사용할 수 있게 해준다. 이미지는 여러 개의 읽기 전용 레이어(Read-only Layer)로 구성되고 파일에 변화(추가, 수정)가 생기면 새로운 레이어가 생성된다.
예를 들어 CentOS 이미지가 C1 + C2 레이어의 집합이라면 이 이미지에서 nginx가 구동되는 환경의 이미지 레이어는 C1 + C2 + nginx 가 된다. 이런 식으로 기존의 이미지 레이어 위에 레이어가 추가되는 방식으로 최소한의 용량을 사용할 수 있게 된다. 여러대의 서버에 배포하는 것을 감안하면 엄청나게 영리한 설계이다.
마치며,
도커를 기반으로 한 오픈소스 프로젝트는 수십만개가 넘어가고 굉장히 활발히 진행되고 있다. 훌륭한 생테계를 기반으로 클라우드 컨테이너 세계에서 de facto(사실상 표준)가 되었다. 이 글에서 도커에 대한 전반적인 역사와 개념을 매우 얕게 정리해보았는데 다음 포스팅부터는 본격적으로 도커의 설치, 컨테이너 관리와 활용 등을 정리해보도록 하겠다.



댓글 없음: